Spark集群安装
机器
如果只有3台主机,可以按照如下规划来部署安装
| IP | host |
|---|---|
| 172.16.185.68 | hadoop1 |
| 172.16.185.69 | hadoop2 |
| 72.16.185.70 | hadoop3 |
Hadoop集群安装
Scala安装
详见Scala安装
下载
进入官网下载,当前使用 spark-2.2.0-bin-hadoop2.6.tgz 版本 ,或者百度云下载
解压
tar -zxvf spark-2.2.0-bin-hadoop2.6.tgz -C /data/
配置Spark环境
此处需要配置的文件为两个 spark-env.sh和slaves
配置spark-env.sh
首先我们把缓存的文件spark-env.sh.template改为spark识别的文件spark-env.sh
cp conf/spark-env.sh.template conf /spark-env.sh
在文件最后加入
export JAVA_HOME=/data/java
export SCALA_HOME=/data/scala-2.12.3
export HADOOP_HOME=/data/hadoop-2.5.2
export HADOOP_CONF_DIR=/data/hadoop-2.5.2/etc/hadoop
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_HOST=hadoop1
export SPARK_LOCAL_IP=hadoop1
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/data/spark-2.2.0-bin-hadoop2.6
export SPARK_DIST_CLASSPATH=$(/data/hadoop-2.5.2/bin/hadoop classpath)
export SPARK_WORKER_INSTANCES=1
变量说明
变量说明
- JAVA_HOME:Java安装目录
- SCALA_HOME:Scala安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
配置slaves
vi conf/slaves
hadoop1
hadoop2
hadoop3
同步到hadoop2和hadoop3机器
在hadoop2和hadoop3上分别修改/etc/profile,增加Spark的配置,过程同Hadoop1一样。
在hadoop2和hadoop3上分别修改 $SPARK_HOME/conf/spark-env.sh,将export SPARK_LOCAL_IP=hadoop1改成hadoop2和hadoop2对应节点的IP。
scp -r /data/spark-2.2.0-bin-hadoop2.6/ hadoop2:/data/spark-2.2.0-bin-hadoop2.6/
scp -r /data/spark-2.2.0-bin-hadoop2.6/ hadoop3:/data/spark-2.2.0-bin-hadoop2.6/
启动Spark集群
因为我们只需要使用hadoop的HDFS文件系统,所以我们并不用把hadoop全部功能都启动。
start-dfs.sh
启动Spark
/data/spark-2.2.0-bin-hadoop2.6/sbin/start-all.sh
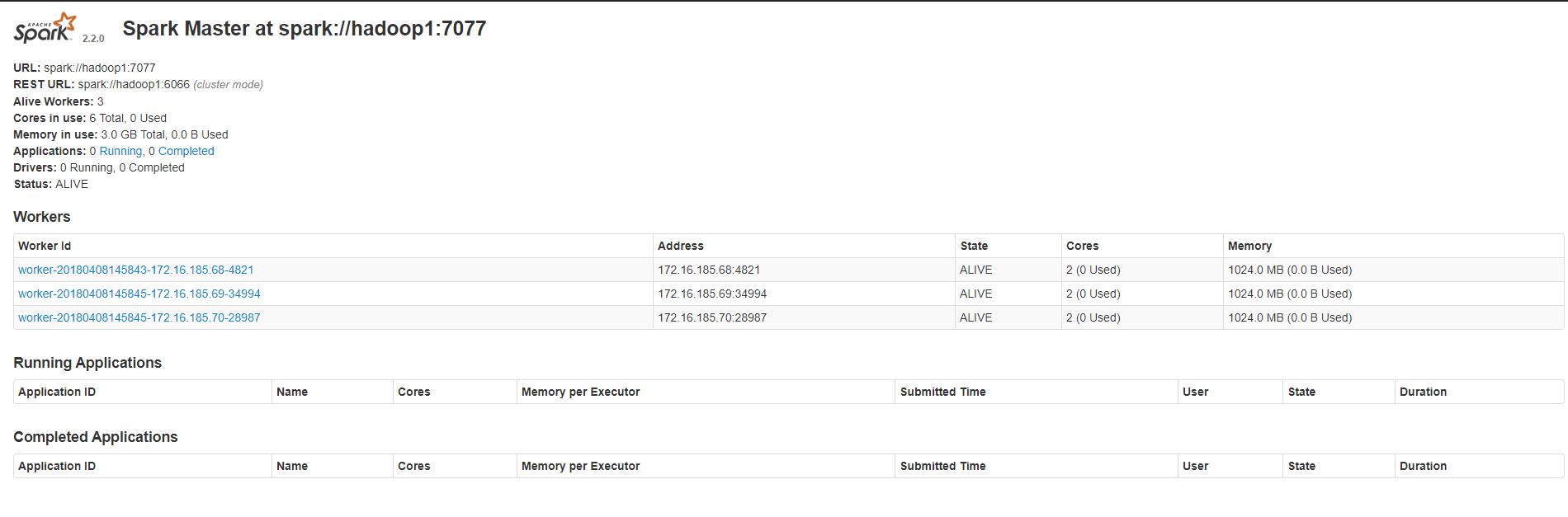
访问 http://hadoop1:8080/
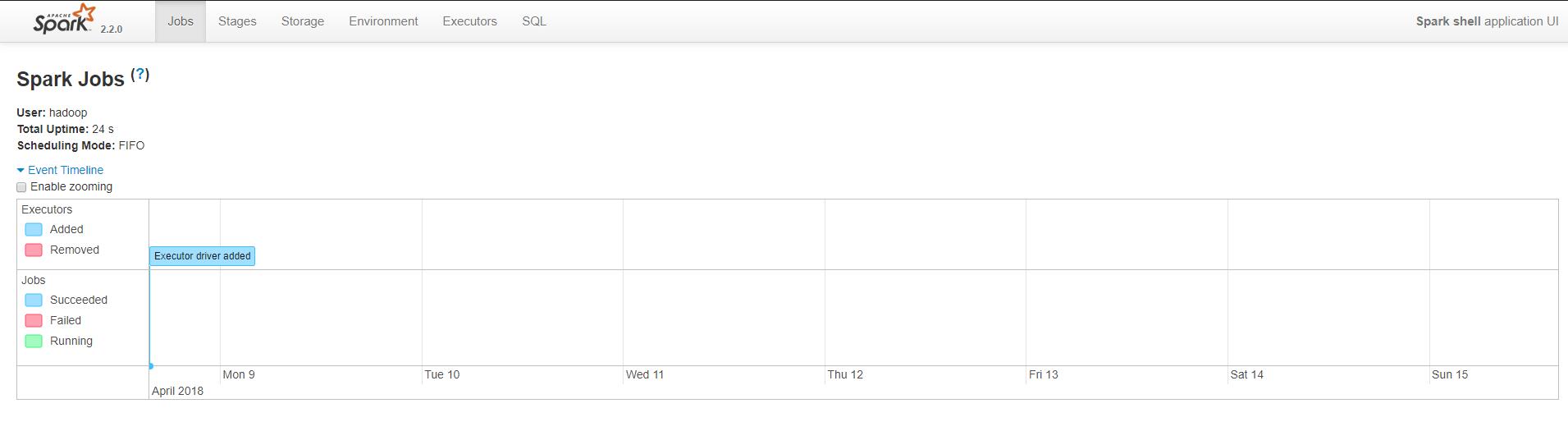
访问WebUI查看当前执行的任务 http://hadoop1:4040/
打开Spark-shell
[hadoop@hadoop1 conf]$ spark-shell
Spark context Web UI available at http://172.16.185.68:4040
Spark context available as 'sc' (master = local[*], app id = local-1523172727212).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
基于zk的HA配置
spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181"
修改hadoop2
export SPARK_MASTER_IP=hadoop2
export SPARK_MASTER_HOST=hadoop2
启动
hadoop1执行
/data/spark-2.2.0-bin-hadoop2.6/sbin/start-all.sh
hadoop2执行
/data/spark-2.2.0-bin-hadoop2.6/sbin/start-master.sh
结果
master
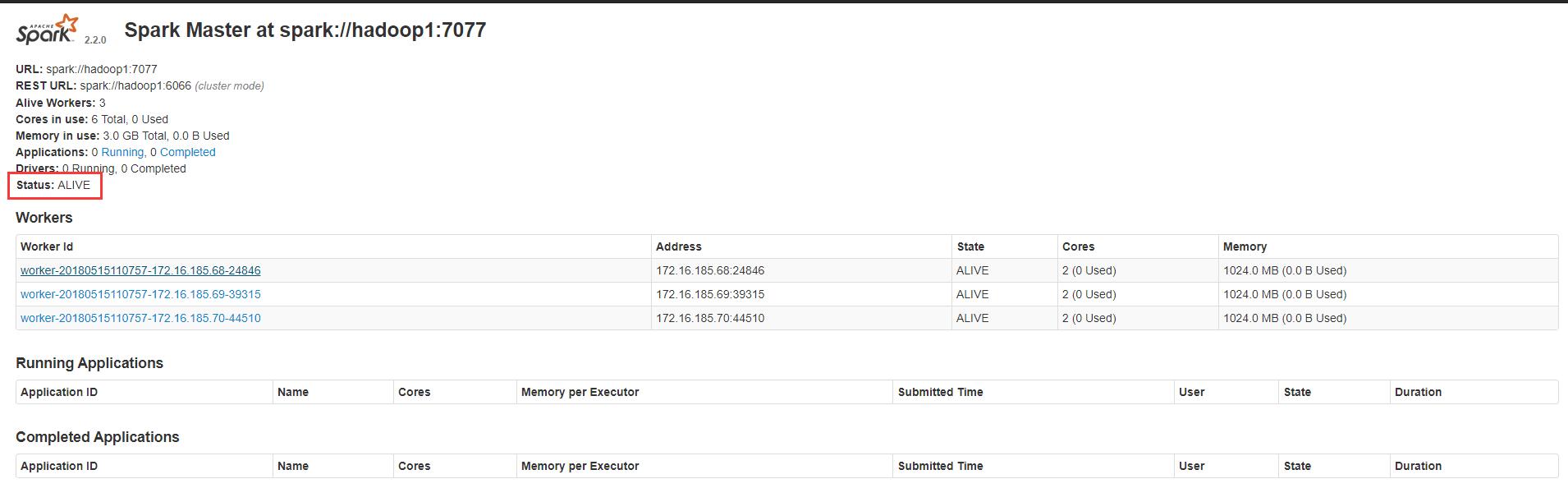
standby
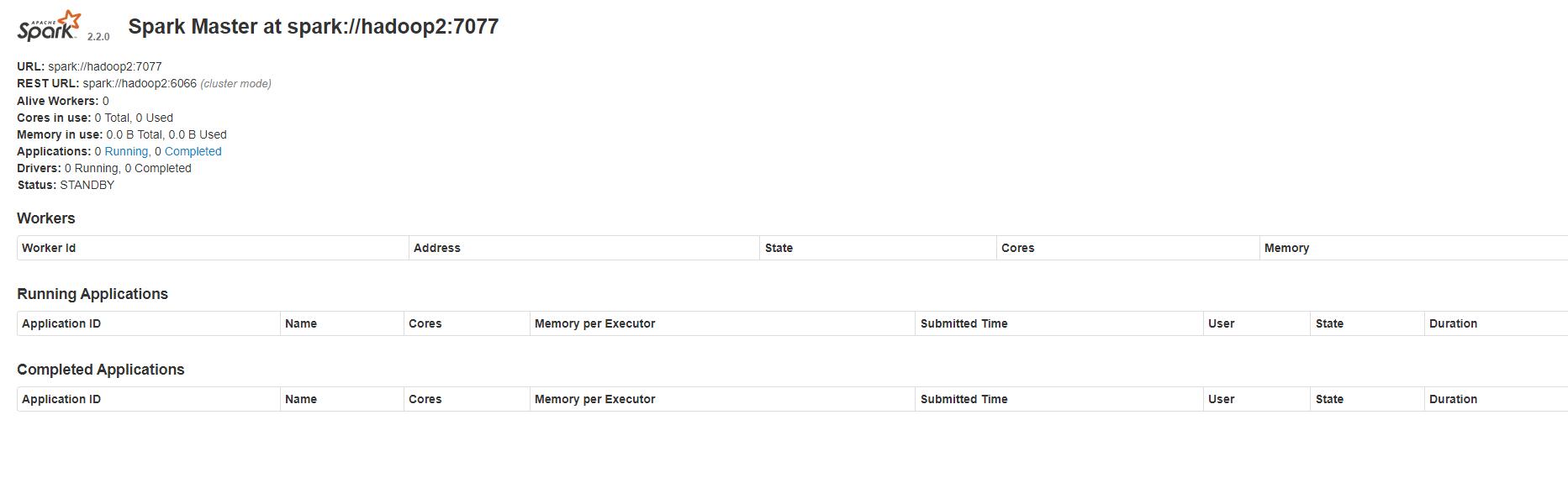
三种模式
local 单机模式
结果xshell可见
/data/spark-2.2.0-bin-hadoop2.6/bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[1] /data/spark-2.2.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.2.0.jar 100
结果
18/05/15 09:53:25 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 2.015707 s
Pi is roughly 3.1409875140987515
18/05/15 09:53:25 INFO server.AbstractConnector: Stopped Spark@54a3ab8f{HTTP/1.1,[http/1.1]}{hadoop1:4040}
18/05/15 09:53:25 INFO ui.SparkUI: Stopped Spark web UI at http://172.16.185.68:4040
18/05/15 09:53:25 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
18/05/15 09:53:25 INFO memory.MemoryStore: MemoryStore cleared
18/05/15 09:53:25 INFO storage.BlockManager: BlockManager stopped
18/05/15 09:53:25 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
18/05/15 09:53:25 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
18/05/15 09:53:25 INFO spark.SparkContext: Successfully stopped SparkContext
18/05/15 09:53:25 INFO util.ShutdownHookManager: Shutdown hook called
18/05/15 09:53:25 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-616236f9-0bec-432b-abd0-fa6eb6e1beb3
standalone集群模式
需要配置 slaves文件
vi conf/slaves
hadoop1
hadoop2
hadoop3
spark-env.sh
export JAVA_HOME=/data/java
export SCALA_HOME=/data/scala-2.12.3
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_HOST=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_LOCAL_IP=hadoop1
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/data/spark-2.2.0-bin-hadoop2.6
export SPARK_DIST_CLASSPATH=$(/data/hadoop-2.5.2/bin/hadoop classpath)
standlonw 情况下有两种:deploy-mode client 和deploy-mode cluster 的区别就是,
client必须在集群上的某个节点执行,所谓的客户端,也就是说提交应用程序的节点要作为整个程序运行的客户端, 也就是说这个节点必须从属于集群!
而cluster顾名思义,就是集群的意思,可以理解为提交的程序在某个集群运行, 也就是说提交的机器只需要拥有单机版的spark环境就行了,至于提交的地方是哪里通过spark://指定就行了, 提交的机器只作为提交的功能,提交完了之后就和他无关了
client模式
结果xshell可见
/data/spark-2.2.0-bin-hadoop2.6/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop1:7077 /data/spark-2.2.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.2.0.jar 100
结果
18/05/15 09:57:16 INFO scheduler.TaskSetManager: Finished task 98.0 in stage 0.0 (TID 98) in 74 ms on 172.16.185.69 (executor 1) (100/100)
18/05/15 09:57:16 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
18/05/15 09:57:16 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 2.562 s
18/05/15 09:57:16 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 2.925183 s
Pi is roughly 3.1411871141187113
18/05/15 09:57:16 INFO server.AbstractConnector: Stopped Spark@46d25622{HTTP/1.1,[http/1.1]}{hadoop1:4040}
18/05/15 09:57:16 INFO ui.SparkUI: Stopped Spark web UI at http://172.16.185.68:4040
18/05/15 09:57:16 INFO cluster.StandaloneSchedulerBackend: Shutting down all executors
18/05/15 09:57:16 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down
18/05/15 09:57:16 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
18/05/15 09:57:16 INFO memory.MemoryStore: MemoryStore cleared
18/05/15 09:57:16 INFO storage.BlockManager: BlockManager stopped
18/05/15 09:57:16 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
18/05/15 09:57:16 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
18/05/15 09:57:16 INFO spark.SparkContext: Successfully stopped SparkContext
18/05/15 09:57:16 INFO util.ShutdownHookManager: Shutdown hook called
18/05/15 09:57:16 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-c3dab551-4fca-4d4a-aca2-f5aabc78168f
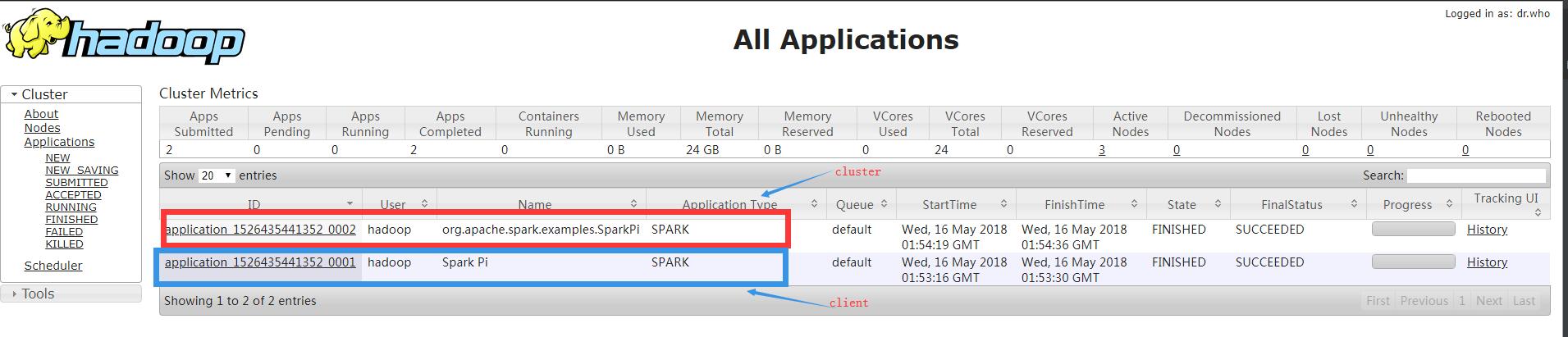
后台 http://hadoop1:8080/ 查看任务
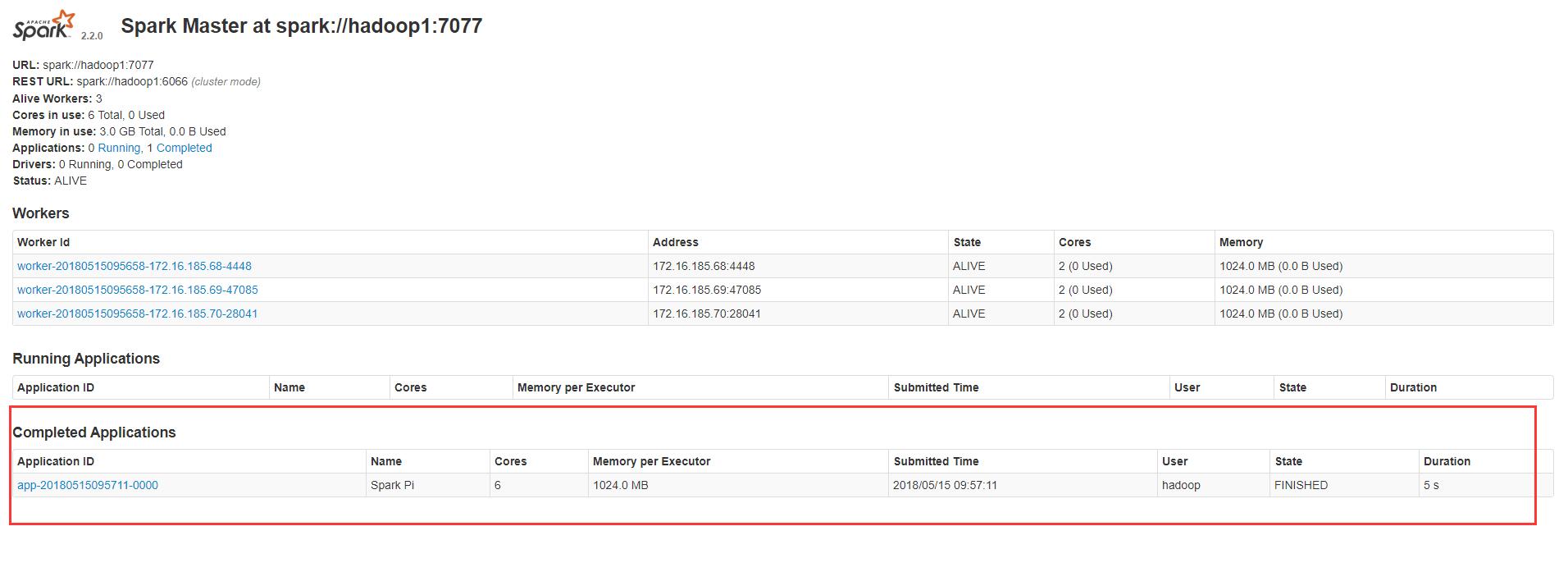
cluster模式
结果http://hadoop1:8080/ 可见
/data/spark-2.2.0-bin-hadoop2.6/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop1:7077 --deploy-mode cluster /data/spark-2.2.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.2.0.jar 100
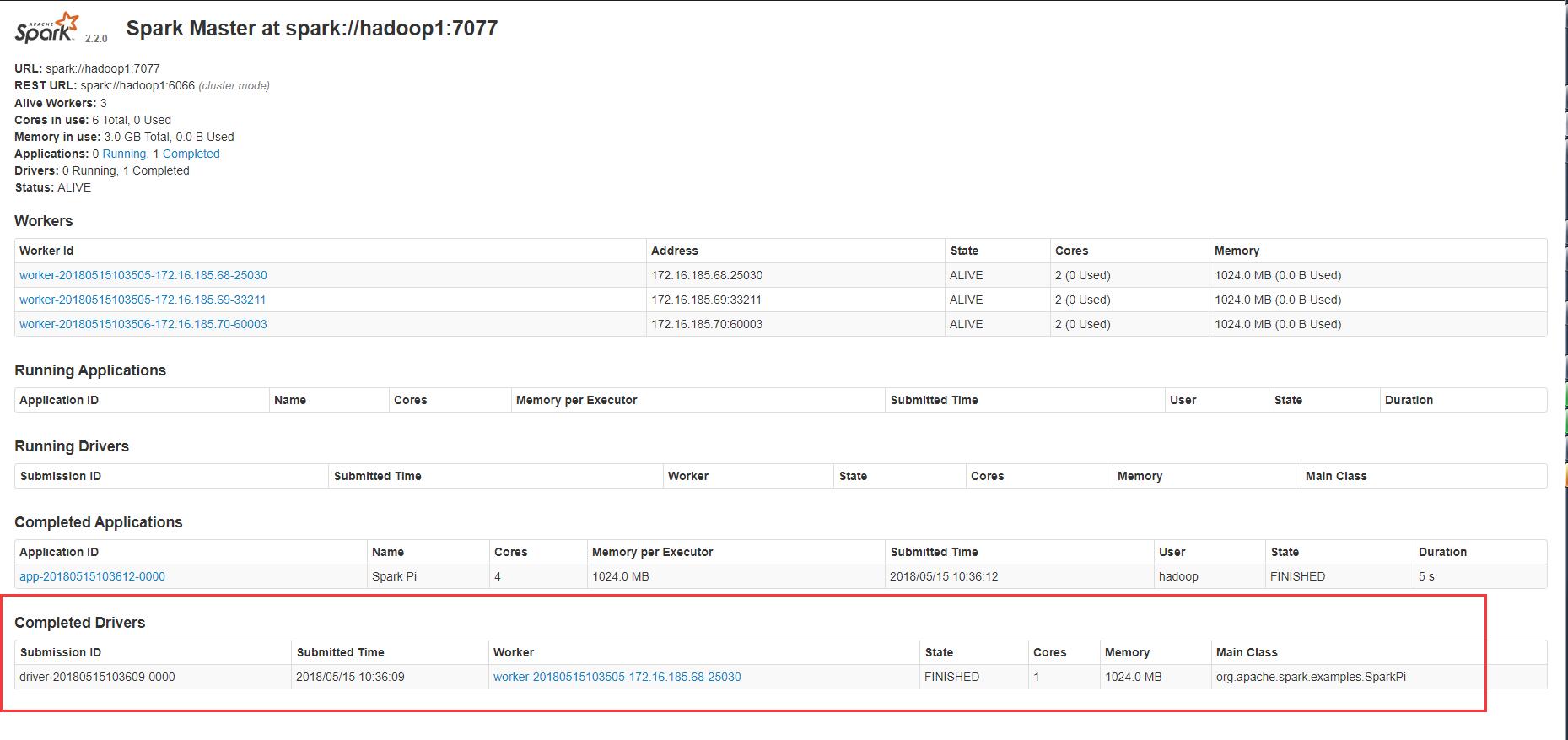
Yarn集群模式
需要配置 slaves文件
vi conf/slaves
hadoop1
hadoop2
hadoop3
spark-env.sh 增加hadoop yarn配置
export HADOOP_CONF_DIR=/data/hadoop-2.5.2/etc/hadoop
export YARN_CONF_DIR=/data/hadoop-2.5.2/etc/hadoop
完整配置
export JAVA_HOME=/data/java
export SCALA_HOME=/data/scala-2.12.3
export HADOOP_HOME=/data/hadoop-2.5.2
export HADOOP_CONF_DIR=/data/hadoop-2.5.2/etc/hadoop
export YARN_CONF_DIR=/data/hadoop-2.5.2/etc/hadoop
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_HOST=hadoop1
export SPARK_LOCAL_IP=hadoop1
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/data/spark-2.2.0-bin-hadoop2.6
export SPARK_DIST_CLASSPATH=$(/data/hadoop-2.5.2/bin/hadoop classpath)
export SPARK_WORKER_INSTANCES=1
只需要启动hadoop环境即可,无需启动spark,此时的任务资源调度全部交给yarn
client模式
结果xshell可见
/data/spark-2.2.0-bin-hadoop2.6/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client /data/spark-2.2.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.2.0.jar 100
18/05/16 09:53:29 INFO scheduler.TaskSetManager: Finished task 97.0 in stage 0.0 (TID 97) in 14 ms on hadoop2 (executor 1) (98/100)
18/05/16 09:53:29 INFO scheduler.TaskSetManager: Starting task 99.0 in stage 0.0 (TID 99, hadoop2, executor 1, partition 99, PROCESS_LOCAL, 4836 bytes)
18/05/16 09:53:29 INFO scheduler.TaskSetManager: Finished task 98.0 in stage 0.0 (TID 98) in 13 ms on hadoop2 (executor 1) (99/100)
18/05/16 09:53:30 INFO scheduler.TaskSetManager: Finished task 99.0 in stage 0.0 (TID 99) in 16 ms on hadoop2 (executor 1) (100/100)
18/05/16 09:53:30 INFO cluster.YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
18/05/16 09:53:30 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 3.572 s
18/05/16 09:53:30 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 3.869407 s
Pi is roughly 3.1421843142184316
18/05/16 09:53:30 INFO server.AbstractConnector: Stopped Spark@2db2cd5{HTTP/1.1,[http/1.1]}{hadoop1:4040}
18/05/16 09:53:30 INFO ui.SparkUI: Stopped Spark web UI at http://172.16.185.68:4040
18/05/16 09:53:30 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
18/05/16 09:53:30 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
18/05/16 09:53:30 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
18/05/16 09:53:30 INFO cluster.SchedulerExtensionServices: Stopping SchedulerExtensionServices
(serviceOption=None,
services=List(),
started=false)
18/05/16 09:53:30 INFO cluster.YarnClientSchedulerBackend: Stopped
18/05/16 09:53:30 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
18/05/16 09:53:30 INFO memory.MemoryStore: MemoryStore cleared
18/05/16 09:53:30 INFO storage.BlockManager: BlockManager stopped
18/05/16 09:53:30 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
http://hadoop1:8088/proxy/application_1526435441352_0011/
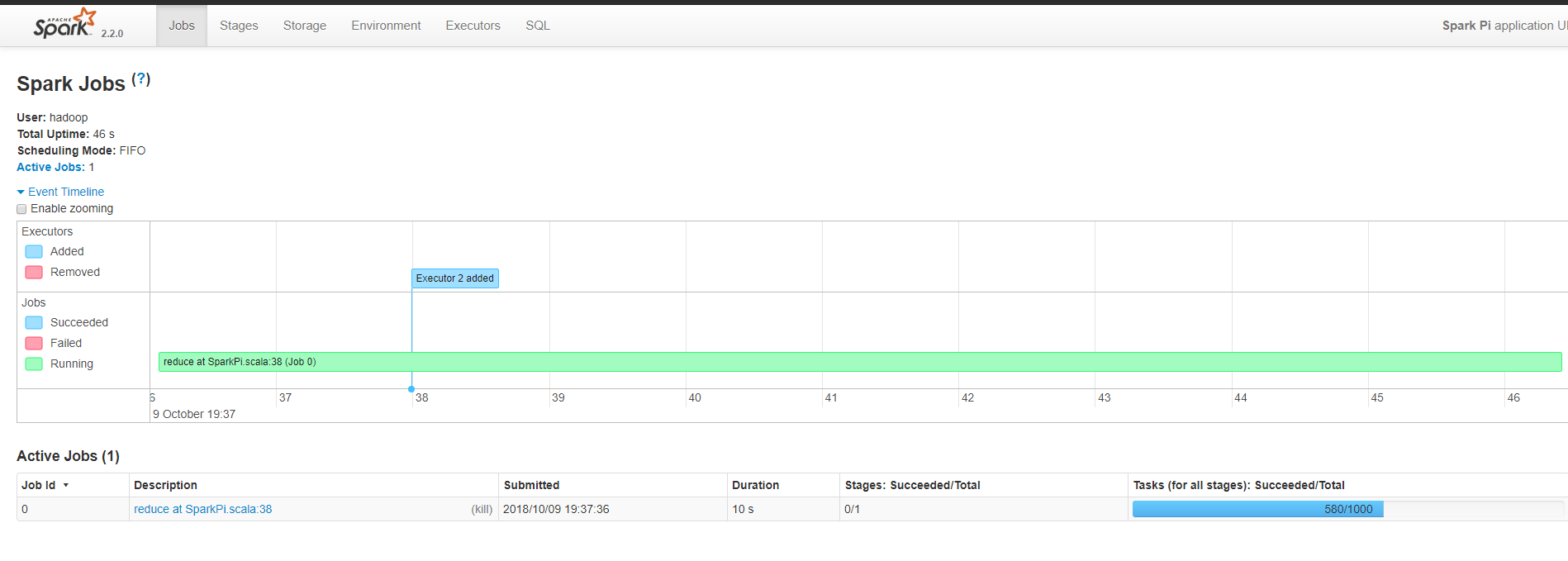
shell启动
spark-shell --master yarn --deploy-mode client
18/05/16 09:54:37 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 172.16.185.70
ApplicationMaster RPC port: 0
queue: default
start time: 1526435659321
final status: SUCCEEDED
tracking URL: http://hadoop1:8088/proxy/application_1526435441352_0002/A
user: hadoop
18/05/16 09:54:37 INFO util.ShutdownHookManager: Shutdown hook called
18/05/16 09:54:37 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-bc92186f-cf94-472e-a8be-f1a1931cd97d
[hadoop@hadoop1 conf]$ spark-shell --master yarn --deploy-mode client
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/05/16 09:56:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/05/16 09:56:38 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
18/05/16 09:57:12 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://172.16.185.68:4040
Spark context available as 'sc' (master = yarn, app id = application_1526435441352_0003).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
cluster模式
/data/spark-2.2.0-bin-hadoop2.6/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster /data/spark-2.2.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.2.0.jar 100
http://hadoop1:8088/cluster